
ML-Agents를 이용해서 환경을 만들고 이를 학습시키보던 중 신기한(?) 현상을 발견했다.
모든 hyperparameter가 같음에도 불구하고 ML-Agents 알고리즘과 SB3(Stable-Baselines3) 알고리즘의 성능 차이가 너무 크게 났던 것이다. (ML-Agents PPO가 SB3 PPO보다 훨씬 우세했다.)
ML-Agents와 SB3의 PPO 코드를 엄청 뜯어보고 고친 결과 SB3 PPO를 이용해 Crawler환경에서 ML-Agents PPO의 성능을 동일하게 재현할 수 있었다.
따라서 이 글에서는 SB3 PPO로 ML-Agents PPO의 성능을 재현하는 방법을 써보려고 한다.
ML-Agents Crawler 환경
본론에 들어가기에 앞서, 테스트에 사용된 Crawler환경에 대해서 간략히 소개를 해보려고 한다.

Crawler환경은 네 다리를 가진 에이전트가 타겟 지점에 도달하는것을 목표로 한다.
구체적인 정보는 다음과 같다.
- Observation Space
- obs_0 : 각 관절과 몸통의 Rigidbody 정보로, $\mathbb{R}^{126}$의 벡터이다.
- obs_1 : 각 관절의 상태와 Goal(목표 지점)에 대한 정보로, $\mathbb{R}^{32}$의 벡터이다.
- Action Space : Crawler의 각 관절들의 제어 입력으로, $\mathbb{R}^{20}$의 벡터이다.
더 자세한 정보는 다음을 참고하면 됩니다. (오래된 정보가 몇개 포함되어 있습니다.)
https://unity-technologies.github.io/ml-agents/Learning-Environment-Examples/
Example Learning Environments - Unity ML-Agents Toolkit
Example Learning Environments The Unity ML-Agents Toolkit includes an expanding set of example environments that highlight the various features of the toolkit. These environments can also serve as templates for new environments or as ways to test new ML al
unity-technologies.github.io
0. UnityEnvironment를 VecEnv로 wrapping하기
이 단계는 ML-Agents와 SB3의 성능이 다른 문제와는 직접적인 연관이 없지만, SB3를 이용해서 학습을 하기 위해서는 필수적이므로 포함시켰다.
SB3에서 어떤 환경을 학습시키려면 기본적으로 gym의 'Env'나 SB3의 `VecEnv`형식으로 환경이 제공되어야 한다.
물론 ML-Agents에서 `UnityToGymWrapper`를 제공하기는 하지만, 이는 병렬 agent를 처리하지 못한다.
따라서 여러 unity build instances를 실행시켜서 `UnityToGymWrapper`로 wrapping한뒤 VecEnv로 만들어 사용해야 하는데 이렇게 하면 매우 느리다.
어느정도로 느리냐면, 아래 후술할 방법으로 4시간정도 걸리는 것이 이 방법을 사용하면 2~3일이나 걸리게 된다.
따라서 나는 ML-Agents의 LLAPI를 이용해서 VecEnv wrapper를 따로 만들었고, 이는 다음과 같다.
https://github.com/asdfGuest/ML-Agents-Toolbox
GitHub - asdfGuest/ML-Agents-Toolbox: Helpful tools for mlagents.
Helpful tools for mlagents. Contribute to asdfGuest/ML-Agents-Toolbox development by creating an account on GitHub.
github.com
1. Hyperparameter
내가 사용한 ML-Agents의 config파일은 다음과 같다.
behaviors:
Crawler:
trainer_type: ppo
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.00025
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 30000여기서 `network_setting > normalize`를 볼 수 있듯이 ML-Agents는 observation normalization을 사용하고 있다.
observation normalization의 사용 여부는 성능에 매우 큰 영향을 미치기에 SB3에서 `VecNormalize`를 꼭 사용하도록 하자.
SB3에서 위와 동일하게 PPO의 hyperparameter를 설정하면 다음과 같다.
model = PPO(
policy=MultiInputPolicy,
env=env,
learning_rate=get_linear_fn(0.0003, 1e-10, 1.0),
n_steps=2048,
batch_size=2048,
n_epochs=3,
gamma=0.995,
gae_lambda=0.95,
clip_range=get_linear_fn(0.2, 0.1, 1.0),
clip_range_vf=None,
ent_coef=get_linear_fn(0.00025, 1e-5, 1.0),
vf_coef=0.5,
max_grad_norm=None,
normalize_advantage=True,
policy_kwargs=dict(
net_arch=dict(pi=[512,512,512], vf=[512,512,512]),
activation_fn=th.nn.SiLU,
ortho_init=False,
log_std_init=0.0
),
verbose=2
)
만약 SB3 PPO를 많이 사용해 보았다면 이상한 점을 찾을 수 있을 것이다.
원래 `max_grad_norm=None`과 `ent_coef=get_linear_fn(0.00025, 1e-5, 1.0)`와 같이 설정하는것은 불가능하다.
이 부분에 대해서는 후술할 구현 차이 때문에 SB3 PPO 코드를 수정해야만 가능하다.
2. ML-Agents와 Stable-Baselines3 PPO의 구현 차이
이제부터 본격적으로 ML-Agents와 Stable-Baselines3의 구현 차이에 대해 다뤄보고자 한다.
1) Clipped Value Loss
SB3와 ML-Agents의 PPO는 모두 clipped value loss를 사용하지만, 구현이 다르게 되어 있다.
따라서 clipped value loss구현을 일치하도록 수정할 수도 있겠지만, 사실 이건 있으나 없으나 성능에 거의 영향을 미치지 않으므로 나는 아얘 사용하지 않았다. (MSE loss를 사용했다.)
2) Advantage Normalization
SB3의 경우 advantage normalization을 batch단위로 수행하지만, ML-Agents의 경우 batch 단위가 아닌 전체 데이터 단위로 수행한다.
이부분 또한 성능에 거의 영향을 미치지 않을것으로 보이지만, 코드에는 반영 해 주었다.
3) Gradient Clipping
SB3는 gradient norm clipping을 사용하지만 ML-Agents는 사용하지 않는다.
나는 이부분이 필요하지 않다고 판단해서 SB3에서 아얘 제거했다.
4) Entropy Coefficient Scheduling
SB3에서는 기본적으로 `ent_coef`의 스케줄링을 지원하지 않는다.
하지만 ML-Agents에서는 `beta`(`ent_coef`와 같다)의 스케줄링 지원하므로 이를 반영하였다.
5) Network Initialization
SB3와 ML-Agents의 네트워크 초기화 방식이 다르기 때문에 ML-Agents의 것과 똑같도록 해줬다.
SB3 PPO 모델에 다음 코드를 적용시켜주면 된다.
def net_init(model:PPO) :
cnt = 0
def init_linear(layer:th.nn.Linear, gain:float=1.0, uniform:bool=False) :
if not isinstance(layer, th.nn.Linear) :
return
global cnt
cnt += 1
if not uniform :
th.nn.init.kaiming_normal_(layer.weight.data, nonlinearity='linear')
else :
th.nn.init.xavier_uniform_(layer.weight.data)
layer.weight.data *= gain
th.nn.init.zeros_(layer.bias.data)
def init_linears(layers, gain:float=1.0) :
for layer in layers :
init_linear(layer, gain)
init_linears(model.policy.mlp_extractor.policy_net, gain=1.0)
init_linears(model.policy.mlp_extractor.value_net, gain=1.0)
init_linear(model.policy.action_net, gain=0.2)
init_linear(model.policy.value_net, gain=1.0, uniform=True)
print('total %d layer was initialized'%(cnt))`total 8 layer was initialized`라고 뜨면 정상이다.
6) Action Clipping
`ml-agents/ml-agents/mlagents/trainers/torch_entities/action_model.py`를 보면 다음과 같은 코드가 있다.
if self.clip_action:
continuous_out = torch.clamp(continuous_out, -3, 3) / 3
action_out_deprecated = continuous_out
deterministic_continuous_out = (
torch.clamp(deterministic_continuous_out, -3, 3) / 3
)
샘플링한 action을 clipping하는 부분이다.
참 이해가 안가는 것이, $[-3,3]$에 대해 clipping한 값에 $/3$을 해준 값을 최종적인 action으로 사용하고 있다.
아마 이 코드를 쓴 사람은 gaussian pdf에서 std에 $/3$을 하는 효과를 의도했을 것이다.
하지만 내 생각에는 이걸 init_log_std값의 조정을 통해서 해야 하는 것이지 샘플링된 action을 clipping하는 단계에서 하드코딩으로 처리하는게 맞는지 모르겠다.
어찌 됐든 나는 action bound를 3배 해주는 ` VecEnvWrapper`를 사용하는것으로 해결해줬다.
해당 `VecEnvWrapper` 또한 ML-Agents-Toolbox에 구현되어 있으니 참고하길 바란다.
7) log_prob, ratio, entropy calculation
드디어 마지막 단계에 왔다.
물론 다른 단계도 중요하긴 하지만, 이 단계가 가장 중요하고, 성능에 미치는 영향도 가장 크다.
SB3 PPO에서 policy loss를 계산하는 부분을 보자.
# ratio between old and new policy, should be one at the first iteration
ratio = th.exp(log_prob - rollout_data.old_log_prob)
# clipped surrogate loss
policy_loss_1 = advantages * ratio
policy_loss_2 = advantages * th.clamp(ratio, 1 - clip_range, 1 + clip_range)
policy_loss = -th.min(policy_loss_1, policy_loss_2).mean()여기서 `log_prob` , `rollout_data.old_log_prob`, `ratio`, `advantages`의 shape에 대해 한번 생각해보면, 이들의 shape은 모두 $(\text{batch_size},)$로 같을 것이다.
다변량 정규분포(Multivariate Gaussian Distribution)에서 `log_prob`과 `entropy`는 각 정규분포의 `log_prob`과 `entropy`를 계산한 뒤 더해주면 된다.
$$
\log P(x_1,x_2,\cdots,x_n) = \sum_{k=1}^{n} \log P(x_k)
$$
$$
H(X_1,X_2,\cdots,X_n) = \sum_{k=1}^{n} H(X_k)
$$
위의 내용에 따라서 각 action의 gaussian pdf에 대해서 계산한 `log_prob`을 action 차원에 대해서 모두 더해주는 것이 맞는 구현이다.
아래는 `stable_baselines3/common/distributions.py`의 코드중 일부인데, `sum_independent_dims`함수를 통해 `log_prob`과 `entropy`를 계산할때 각 action 차원에 대해서 더해주는것을 확인할 수 있다.
def log_prob(self, actions: th.Tensor) -> th.Tensor:
"""
Get the log probabilities of actions according to the distribution.
Note that you must first call the ``proba_distribution()`` method.
:param actions:
:return:
"""
log_prob = self.distribution.log_prob(actions)
return sum_independent_dims(log_prob)
def entropy(self) -> Optional[th.Tensor]:
return sum_independent_dims(self.distribution.entropy())
그럼 과연 ML-Agents는 `log_prob`과 `entropy`를 잘 계산하고 있을까?
결론부터 이야기 하면 ML-Agents에서는 `log_prob`과 `entropy`를 계산할때 각 action 차원에 대해서 더해주지 않는다.
ML-Agents에서는 `log_prob`, `entropy`, `ratio`, `advantage` 모두 shape이 $(\text{batch_size},\text{action_dim})$인 상태로 계산된다.
이러면 문제가 되는것이, 구현이 알고리즘의 이론과 달라져서 이론적인 optimal point가 달라질 뿐만 아니라, policy loss에 의한 gradient scale과 entropy term에 의한 gradient scale이 달라지게 된다.
그런데 애초에 지금 하던 것이 SB3 PPO의 낮은 성능을 ML-Agents PPO까지 끌어올리는 것인데, ML-Agents PPO 방식의 구현이 이론과는 다를지라고 성능이 훨씬 뛰어나게 나오기 때문에 SB3를 수정하는 방향을 선택했다.
(`entropy`의 경우는 ML-Agents의 코드를 수정했다.)
3. Stable-Baselines3 코드 수정사항
SB3 코드는 다음과 같이 수정하면 된다.
- `stable_baselines3/ppo/ppo.py` : https://www.diffchecker.com/L9KLaUxa/
- `ent_coef` scheduling 추가
- `advantage_mean`, `advantage_std`를 전체 데이터 셋에 대해 계산
- policy loss를 계산할때 `log_prob`, `ratio`의 shape을 $(\text{batch_size},\text{action_dim})$으로 수정
- gradient clipping 제거
- `stable_baselines3/common/distributions.py` : https://www.diffchecker.com/ltL8Yabu/
- `log_prob`을 계산할때 `sum_independent_dims` 제거
- `stable_baselines3/common/buffers.py` : https://www.diffchecker.com/yOuLfCe8/
- `log_probs`의 shape을 $(\text{buffer_size},\text{n_envs}) \rightarrow (\text{buffer_size},\text{n_envs},\text{action_dim})$로 수정
4. ML-Agents 코드 수정사항
ML-Agents의 경우 다음과 같이 수정하면 된다.
- `mlagents/trainers/torch_entities/utils.py` : https://www.diffchecker.com/obKgL9Fh/
- value loss를 계산할때 MSE만 사용하도록 수정
- `mlagents/trainers/torch_entities/distributions.py` : https://www.diffchecker.com/4s3qy51g/
- `entropy`를 계산할때 action 차원에 대해서 `mean`을 `sum`으로 변경
5. 요약
지금까지 SB3 PPO로 ML-Agents PPO의 성능을 내기 위해 필요한 부분들을 요약하면 다음과 같다.
- Hyperparameter
- `VecNormalize`
- MSE Value Loss
- 전체 데이터에 대한 Advantage Normalization
- Gradient Clipping 사용 X
- Entropy Coefficient Scheduling
- Network Initialization
- Action Clipping
- log_prob, ratio, entropy calculation
결과적으로 추가하거나 수정해야 하는 코드는 다음과 같다.
- `UnityVecEnv` : ML-Agents-Toolbox 를 사용할 수 있음
- PPO model hyperparameter
- `VecNormalize`사용
- Stable-Baselines3
- `stable_baselines3/ppo/ppo.py`
- `stable_baselines3/common/distributions.py`
- `stable_baselines3/common/buffers.py`
- ML-Agents
- `mlagents/trainers/torch_entities/utils.py`
- `mlagents/trainers/torch_entities/distributions.py`
결과
지금까지의 과정을 잘 따라왔다면 SB3 PPO로 Crawler를 학습시킬 수 있을 것이다.
나는 그램을 사용해서 학습시켰고, 약 240분 정도 소요되었다.
최종 성능은 stochastic policy 기준 3100~3200의 점수를 보여준다. (x축은 무시하자)
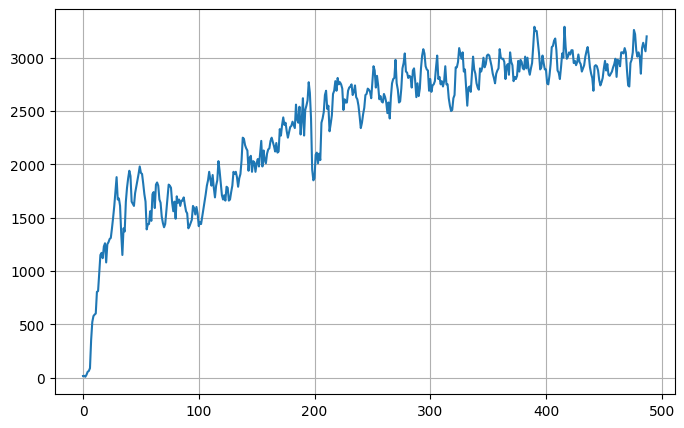
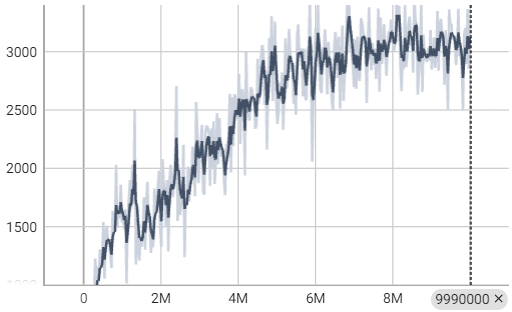
사실상 ML-Agent PPO와 똑같은 결과를 보여주지만, 단 하나 entropy curve가 다르긴 하다.
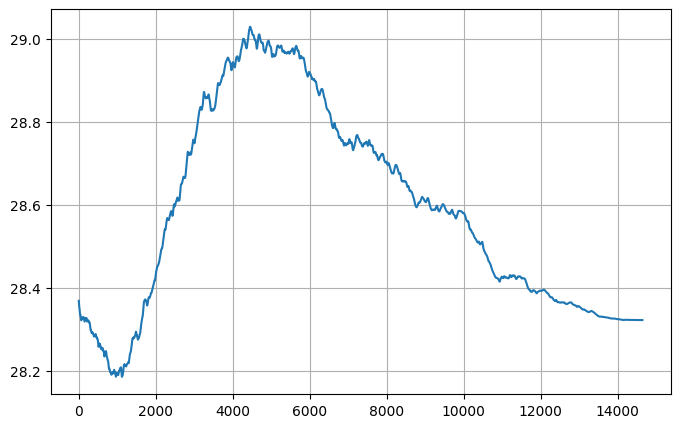
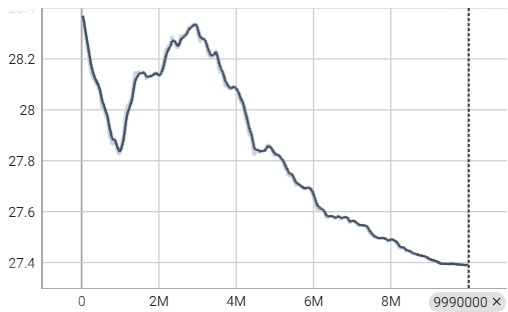
이유는 찾지 못했는데, 아마 내가 찾지 못한 구현 차이에서 온 결과인 듯 하다.
(예를들면, observation normalize 부분이 다르게 구현되어 있다.)
어찌됬든 성능은 잘 나오고 entropy curve의 이정도 차이는 그리 중요한게 아니므로 요정도로 마무리 하려고 한다.
'인공지능' 카테고리의 다른 글
| Backpropagation Vectorization (1) | 2024.03.23 |
|---|---|
| Cross Entropy Derivation (0) | 2024.03.11 |
| CS234 Notes - Lecture 2 번역본 (0) | 2023.11.17 |
| RNN - Recurrent neural network (0) | 2023.09.11 |
| 머신러닝에 쓰이는 정보이론 (0) | 2023.09.04 |
ML-Agents를 이용해서 환경을 만들고 이를 학습시키보던 중 신기한(?) 현상을 발견했다.
모든 hyperparameter가 같음에도 불구하고 ML-Agents 알고리즘과 SB3(Stable-Baselines3) 알고리즘의 성능 차이가 너무 크게 났던 것이다. (ML-Agents PPO가 SB3 PPO보다 훨씬 우세했다.)
ML-Agents와 SB3의 PPO 코드를 엄청 뜯어보고 고친 결과 SB3 PPO를 이용해 Crawler환경에서 ML-Agents PPO의 성능을 동일하게 재현할 수 있었다.
따라서 이 글에서는 SB3 PPO로 ML-Agents PPO의 성능을 재현하는 방법을 써보려고 한다.
ML-Agents Crawler 환경
본론에 들어가기에 앞서, 테스트에 사용된 Crawler환경에 대해서 간략히 소개를 해보려고 한다.
Crawler환경은 네 다리를 가진 에이전트가 타겟 지점에 도달하는것을 목표로 한다.
구체적인 정보는 다음과 같다.
- Observation Space
- obs_0 : 각 관절과 몸통의 Rigidbody 정보로, $\mathbb{R}^{126}$의 벡터이다.
- obs_1 : 각 관절의 상태와 Goal(목표 지점)에 대한 정보로, $\mathbb{R}^{32}$의 벡터이다.
- Action Space : Crawler의 각 관절들의 제어 입력으로, $\mathbb{R}^{20}$의 벡터이다.
더 자세한 정보는 다음을 참고하면 됩니다. (오래된 정보가 몇개 포함되어 있습니다.)
https://unity-technologies.github.io/ml-agents/Learning-Environment-Examples/
Example Learning Environments - Unity ML-Agents Toolkit
Example Learning Environments The Unity ML-Agents Toolkit includes an expanding set of example environments that highlight the various features of the toolkit. These environments can also serve as templates for new environments or as ways to test new ML al
unity-technologies.github.io
0. UnityEnvironment를 VecEnv로 wrapping하기
이 단계는 ML-Agents와 SB3의 성능이 다른 문제와는 직접적인 연관이 없지만, SB3를 이용해서 학습을 하기 위해서는 필수적이므로 포함시켰다.
SB3에서 어떤 환경을 학습시키려면 기본적으로 gym의 'Env'나 SB3의 VecEnv형식으로 환경이 제공되어야 한다.
물론 ML-Agents에서 UnityToGymWrapper를 제공하기는 하지만, 이는 병렬 agent를 처리하지 못한다.
따라서 여러 unity build instances를 실행시켜서 UnityToGymWrapper로 wrapping한뒤 VecEnv로 만들어 사용해야 하는데 이렇게 하면 매우 느리다.
어느정도로 느리냐면, 아래 후술할 방법으로 4시간정도 걸리는 것이 이 방법을 사용하면 2~3일이나 걸리게 된다.
따라서 나는 ML-Agents의 LLAPI를 이용해서 VecEnv wrapper를 따로 만들었고, 이는 다음과 같다.
https://github.com/asdfGuest/ML-Agents-Toolbox
GitHub - asdfGuest/ML-Agents-Toolbox: Helpful tools for mlagents.
Helpful tools for mlagents. Contribute to asdfGuest/ML-Agents-Toolbox development by creating an account on GitHub.
github.com
1. Hyperparameter
내가 사용한 ML-Agents의 config파일은 다음과 같다.
behaviors:
Crawler:
trainer_type: ppo
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.00025
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 30000여기서 network_setting > normalize를 볼 수 있듯이 ML-Agents는 observation normalization을 사용하고 있다.
observation normalization의 사용 여부는 성능에 매우 큰 영향을 미치기에 SB3에서 VecNormalize를 꼭 사용하도록 하자.
SB3에서 위와 동일하게 PPO의 hyperparameter를 설정하면 다음과 같다.
model = PPO(
policy=MultiInputPolicy,
env=env,
learning_rate=get_linear_fn(0.0003, 1e-10, 1.0),
n_steps=2048,
batch_size=2048,
n_epochs=3,
gamma=0.995,
gae_lambda=0.95,
clip_range=get_linear_fn(0.2, 0.1, 1.0),
clip_range_vf=None,
ent_coef=get_linear_fn(0.00025, 1e-5, 1.0),
vf_coef=0.5,
max_grad_norm=None,
normalize_advantage=True,
policy_kwargs=dict(
net_arch=dict(pi=[512,512,512], vf=[512,512,512]),
activation_fn=th.nn.SiLU,
ortho_init=False,
log_std_init=0.0
),
verbose=2
)
만약 SB3 PPO를 많이 사용해 보았다면 이상한 점을 찾을 수 있을 것이다.
원래 max_grad_norm=None과 ent_coef=get_linear_fn(0.00025, 1e-5, 1.0)와 같이 설정하는것은 불가능하다.
이 부분에 대해서는 후술할 구현 차이 때문에 SB3 PPO 코드를 수정해야만 가능하다.
2. ML-Agents와 Stable-Baselines3 PPO의 구현 차이
이제부터 본격적으로 ML-Agents와 Stable-Baselines3의 구현 차이에 대해 다뤄보고자 한다.
1) Clipped Value Loss
SB3와 ML-Agents의 PPO는 모두 clipped value loss를 사용하지만, 구현이 다르게 되어 있다.
따라서 clipped value loss구현을 일치하도록 수정할 수도 있겠지만, 사실 이건 있으나 없으나 성능에 거의 영향을 미치지 않으므로 나는 아얘 사용하지 않았다. (MSE loss를 사용했다.)
2) Advantage Normalization
SB3의 경우 advantage normalization을 batch단위로 수행하지만, ML-Agents의 경우 batch 단위가 아닌 전체 데이터 단위로 수행한다.
이부분 또한 성능에 거의 영향을 미치지 않을것으로 보이지만, 코드에는 반영 해 주었다.
3) Gradient Clipping
SB3는 gradient norm clipping을 사용하지만 ML-Agents는 사용하지 않는다.
나는 이부분이 필요하지 않다고 판단해서 SB3에서 아얘 제거했다.
4) Entropy Coefficient Scheduling
SB3에서는 기본적으로 ent_coef의 스케줄링을 지원하지 않는다.
하지만 ML-Agents에서는 beta(ent_coef와 같다)의 스케줄링 지원하므로 이를 반영하였다.
5) Network Initialization
SB3와 ML-Agents의 네트워크 초기화 방식이 다르기 때문에 ML-Agents의 것과 똑같도록 해줬다.
SB3 PPO 모델에 다음 코드를 적용시켜주면 된다.
def net_init(model:PPO) :
cnt = 0
def init_linear(layer:th.nn.Linear, gain:float=1.0, uniform:bool=False) :
if not isinstance(layer, th.nn.Linear) :
return
global cnt
cnt += 1
if not uniform :
th.nn.init.kaiming_normal_(layer.weight.data, nonlinearity='linear')
else :
th.nn.init.xavier_uniform_(layer.weight.data)
layer.weight.data *= gain
th.nn.init.zeros_(layer.bias.data)
def init_linears(layers, gain:float=1.0) :
for layer in layers :
init_linear(layer, gain)
init_linears(model.policy.mlp_extractor.policy_net, gain=1.0)
init_linears(model.policy.mlp_extractor.value_net, gain=1.0)
init_linear(model.policy.action_net, gain=0.2)
init_linear(model.policy.value_net, gain=1.0, uniform=True)
print('total %d layer was initialized'%(cnt))total 8 layer was initialized라고 뜨면 정상이다.
6) Action Clipping
ml-agents/ml-agents/mlagents/trainers/torch_entities/action_model.py를 보면 다음과 같은 코드가 있다.
if self.clip_action:
continuous_out = torch.clamp(continuous_out, -3, 3) / 3
action_out_deprecated = continuous_out
deterministic_continuous_out = (
torch.clamp(deterministic_continuous_out, -3, 3) / 3
)
샘플링한 action을 clipping하는 부분이다.
참 이해가 안가는 것이, $[-3,3]$에 대해 clipping한 값에 $/3$을 해준 값을 최종적인 action으로 사용하고 있다.
아마 이 코드를 쓴 사람은 gaussian pdf에서 std에 $/3$을 하는 효과를 의도했을 것이다.
하지만 내 생각에는 이걸 init_log_std값의 조정을 통해서 해야 하는 것이지 샘플링된 action을 clipping하는 단계에서 하드코딩으로 처리하는게 맞는지 모르겠다.
어찌 됐든 나는 action bound를 3배 해주는 VecEnvWrapper를 사용하는것으로 해결해줬다.
해당 VecEnvWrapper 또한 ML-Agents-Toolbox에 구현되어 있으니 참고하길 바란다.
7) log_prob, ratio, entropy calculation
드디어 마지막 단계에 왔다.
물론 다른 단계도 중요하긴 하지만, 이 단계가 가장 중요하고, 성능에 미치는 영향도 가장 크다.
SB3 PPO에서 policy loss를 계산하는 부분을 보자.
# ratio between old and new policy, should be one at the first iteration
ratio = th.exp(log_prob - rollout_data.old_log_prob)
# clipped surrogate loss
policy_loss_1 = advantages * ratio
policy_loss_2 = advantages * th.clamp(ratio, 1 - clip_range, 1 + clip_range)
policy_loss = -th.min(policy_loss_1, policy_loss_2).mean()여기서 log_prob , rollout_data.old_log_prob, ratio, advantages의 shape에 대해 한번 생각해보면, 이들의 shape은 모두 $(\text{batch_size},)$로 같을 것이다.
다변량 정규분포(Multivariate Gaussian Distribution)에서log_prob과entropy는 각 정규분포의log_prob과entropy를 계산한 뒤 더해주면 된다.
$$
\log P(x_1,x_2,\cdots,x_n) = \sum_{k=1}^{n} \log P(x_k)
$$
$$
H(X_1,X_2,\cdots,X_n) = \sum_{k=1}^{n} H(X_k)
$$
위의 내용에 따라서 각 action의 gaussian pdf에 대해서 계산한 log_prob을 action 차원에 대해서 모두 더해주는 것이 맞는 구현이다.
아래는 stable_baselines3/common/distributions.py의 코드중 일부인데, sum_independent_dims함수를 통해 log_prob과 entropy를 계산할때 각 action 차원에 대해서 더해주는것을 확인할 수 있다.
def log_prob(self, actions: th.Tensor) -> th.Tensor:
"""
Get the log probabilities of actions according to the distribution.
Note that you must first call the ``proba_distribution()`` method.
:param actions:
:return:
"""
log_prob = self.distribution.log_prob(actions)
return sum_independent_dims(log_prob)
def entropy(self) -> Optional[th.Tensor]:
return sum_independent_dims(self.distribution.entropy())
그럼 과연 ML-Agents는 log_prob과 entropy를 잘 계산하고 있을까?
결론부터 이야기 하면 ML-Agents에서는 log_prob과 entropy를 계산할때 각 action 차원에 대해서 더해주지 않는다.
ML-Agents에서는 log_prob, entropy, ratio, advantage 모두 shape이 $(\text{batch_size},\text{action_dim})$인 상태로 계산된다.
이러면 문제가 되는것이, 구현이 알고리즘의 이론과 달라져서 이론적인 optimal point가 달라질 뿐만 아니라, policy loss에 의한 gradient scale과 entropy term에 의한 gradient scale이 달라지게 된다.
그런데 애초에 지금 하던 것이 SB3 PPO의 낮은 성능을 ML-Agents PPO까지 끌어올리는 것인데, ML-Agents PPO 방식의 구현이 이론과는 다를지라고 성능이 훨씬 뛰어나게 나오기 때문에 SB3를 수정하는 방향을 선택했다.
(entropy의 경우는 ML-Agents의 코드를 수정했다.)
3. Stable-Baselines3 코드 수정사항
SB3 코드는 다음과 같이 수정하면 된다.
stable_baselines3/ppo/ppo.py: https://www.diffchecker.com/L9KLaUxa/
ent_coefscheduling 추가advantage_mean,advantage_std를 전체 데이터 셋에 대해 계산- policy loss를 계산할때
log_prob,ratio의 shape을 $(\text{batch_size},\text{action_dim})$으로 수정 - gradient clipping 제거
stable_baselines3/common/distributions.py: https://www.diffchecker.com/ltL8Yabu/-
log_prob을 계산할때sum_independent_dims제거
-
stable_baselines3/common/buffers.py: https://www.diffchecker.com/yOuLfCe8/log_probs의 shape을 $(\text{buffer_size},\text{n_envs}) \rightarrow (\text{buffer_size},\text{n_envs},\text{action_dim})$로 수정
4. ML-Agents 코드 수정사항
ML-Agents의 경우 다음과 같이 수정하면 된다.
mlagents/trainers/torch_entities/utils.py: https://www.diffchecker.com/obKgL9Fh/- value loss를 계산할때 MSE만 사용하도록 수정
mlagents/trainers/torch_entities/distributions.py: https://www.diffchecker.com/4s3qy51g/entropy를 계산할때 action 차원에 대해서mean을sum으로 변경
5. 요약
지금까지 SB3 PPO로 ML-Agents PPO의 성능을 내기 위해 필요한 부분들을 요약하면 다음과 같다.
- Hyperparameter
VecNormalize- MSE Value Loss
- 전체 데이터에 대한 Advantage Normalization
- Gradient Clipping 사용 X
- Entropy Coefficient Scheduling
- Network Initialization
- Action Clipping
- log_prob, ratio, entropy calculation
결과적으로 추가하거나 수정해야 하는 코드는 다음과 같다.
UnityVecEnv: ML-Agents-Toolbox 를 사용할 수 있음- PPO model hyperparameter
VecNormalize사용- Stable-Baselines3
stable_baselines3/ppo/ppo.pystable_baselines3/common/distributions.pystable_baselines3/common/buffers.py
- ML-Agents
mlagents/trainers/torch_entities/utils.pymlagents/trainers/torch_entities/distributions.py
결과
지금까지의 과정을 잘 따라왔다면 SB3 PPO로 Crawler를 학습시킬 수 있을 것이다.
나는 그램을 사용해서 학습시켰고, 약 240분 정도 소요되었다.
최종 성능은 stochastic policy 기준 3100~3200의 점수를 보여준다. (x축은 무시하자)
사실상 ML-Agent PPO와 똑같은 결과를 보여주지만, 단 하나 entropy curve가 다르긴 하다.
이유는 찾지 못했는데, 아마 내가 찾지 못한 구현 차이에서 온 결과인 듯 하다.
(예를들면, observation normalize 부분이 다르게 구현되어 있다.)
어찌됬든 성능은 잘 나오고 entropy curve의 이정도 차이는 그리 중요한게 아니므로 요정도로 마무리 하려고 한다.
'인공지능' 카테고리의 다른 글
| Backpropagation Vectorization (1) | 2024.03.23 |
|---|---|
| Cross Entropy Derivation (0) | 2024.03.11 |
| CS234 Notes - Lecture 2 번역본 (0) | 2023.11.17 |
| RNN - Recurrent neural network (0) | 2023.09.11 |
| 머신러닝에 쓰이는 정보이론 (0) | 2023.09.04 |